rabbitMq的学习
序言
你在系统中是否写过这样的接口:客户端访问服务器,服务器进行了大量逻辑/耗时操作之后,才能将结果返回给客户端,而这时,客户端的连接或许已经因为超时而关闭了。 为了能够及时的给客户端返回数据,在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。 RabbitMQ是一个在AMQP基础上完成的,可复用的企业消息系统。RabbitMQ用Erlang语言编写,支持多种消息协议,消息队列,传送确认,可以将消息灵活的路由到队列,并支持多种交换类型。同时也可部署为负载均衡的集群,实现高可用性和吞吐量,联跨多个可用性区域和地区。RabbitMQ支持Java, .NET, PHP, Python, JavaScript, Ruby, Go等多种语言,方便开发者使用。
基础介绍
在使用RabbitMQ之前,需要了解一些RabbitMQ的基础知识,这些基础知识最好还是要了解的,否则在面对Spring中配置文件的时候会有很多疑惑。
Queue
MQ就是Message Queuing,Queue就是队列了。在RabbitMQ中,Queue是最主要的地方,Message Queuing就是存储Message的队列。 生产者Producer(以下简写为p)将消息投递到Message Queuing(以下简写为q)中,消费者(以下简写为c)从queue中获取消息进行处理。 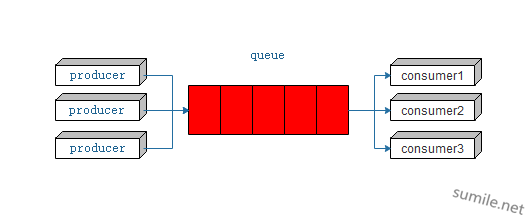 如上图中所画(图中缺少exchange,下面会说到)的那样,多个p将消息交给了q,然后就不关心系统怎么处理这些消息了。而q在收到这些消息后,会分发给在它这里注册了的c,让他们去分别处理。每一条消息只会分发给一个c,而不是每一个c接受到所有的消息然后全部去处理。
如上图中所画(图中缺少exchange,下面会说到)的那样,多个p将消息交给了q,然后就不关心系统怎么处理这些消息了。而q在收到这些消息后,会分发给在它这里注册了的c,让他们去分别处理。每一条消息只会分发给一个c,而不是每一个c接受到所有的消息然后全部去处理。
Producer
Producer负责产生消息并将消息发送给Queue,它不关心消息怎么处理,只把消息按照指定的规则(下面会说)发送出去。
Consumer
系统在启动的时候,会将所有的消费者Consumer注册到RabbitMQ中并对指定的Queue(有规则,下面会说)进行监听,如果Queue中产生了数据,queue会将消息平摊发送给所有注册到当前quene中的consumer中,由consumer进行处理。
Exchange
Exchange在RabbitMQ中是一个很重要的组件。 上面我们说Producer负责产生消息并将消息发送给Queue,实际上Producer并不直接连接Queue,而是连接了Exchange,由Exchange将消息路由到指定的Queue中。也就是在producer和queue中间插入了一个Exchange来分发消息给queue。 ExchangeType、binding和ExchangeName三者确定了一个Exchange,ExchangeName确定了这个Exchange的名字,ExchangeType决定了这是一个什么类型的Exchange,binding决定了它以什么规则连接一个queue。
- ExchangeName标记了这个Exchange,在producer发送消息的时候需要指定,消息会发送到指定ExchangeName的Exchange中。比如说你去参加婚礼宴会,主人之前告诉你到了酒店去大厅找服务员A,她会带你到包厢。这里的“服务员A”这个名字就是ExchangeName
- binding(其实是一个字符串或者说一种特别的正则)会将Exchange和Queue联系起来,而Exchange路由到Queue的规则就是这个binding/binding-key。比如说你去参加一个婚宴,请帖写着302包厢,那服务员就会领着你到302包厢。在这个例子中,服务员就是Exchange,包厢是queue,而服务员脑中这个“根据你的请柬领你到哪个包厢”的规则就是binding。而你的请柬是routing-key,这个后面说
- ExchangeType是Exchange的类型,这决定了这个Exchange会执行哪种规则(binding)将消息路由到不同的queue。ExchangeType分为多种,其中最为常用的就是direct,fanout和topic。还是比如你去参加婚宴,婚宴上可能有很多服务员。
-
服务员A是个耿直boy,你请柬上写着哪个包厢他就领你去哪个包厢,也就是你的请柬上的“302包厢”和他脑中“302包厢(302包厢在3楼第二个包厢)”是相等的,那他就领着你去了,这个服务员就叫“direct”。
-
而服务员B他负责领路到4楼的401、402包厢,另外他是个呆子但是会一点魔法,不管是谁找到他,他都会念一句魔法把你复制两份(有几个包厢就复制几份),然后把你分别领到他负责的包厢去,401、402包厢每一个都有一个你,这个服务员是“fanout”,你在这个例子中就是消息(意即如果消息发送给type是fanout的exchange,exchange会把消息发送给所有和他绑定的queue中)。
-
最后有一个服务员C特别聪明,老板交给他的任务是如果找你的是男人,领到501,如果是女人,领到502,如果是小孩子,领到503,即按照不同的规则(这里的规则更详细的解释可以解释成:*.男人.人路由到501,*.女人.人路由到502,*.小孩.人路由到503),这个服务员就叫“topic”,topic的详细规则是这样的:
1
2
3routing key为一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”
binding key与routing key一样也是句点号“. ”分隔的字符串
binding key中可以存在两种特殊字符“*”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
1
2
3
4
5以上图中的配置为例,routingKey=”quick.orange.rabbit”的消息会同时路由到Q1与Q2,
routingKey=”lazy.orange.fox”的消息会路由到Q1与Q2,
routingKey=”lazy.brown.fox”的消息会路由到Q2,
routingKey=”lazy.pink.rabbit”的消息会路由到Q2(只会投递给Q2一次,虽然这个routingKey与Q2的两个bindingKey都匹配);
routingKey=”quick.brown.fox”、routingKey=”orange”、routingKey=”quick.orange.male.rabbit”的消息将会被丢弃,因为它们没有匹配任何bindingKey。参考自:RabbitMQ基础概念详细介绍
-
介绍Producer和Consumer的规则
上面在介绍Producer的时候都把规则给略过了,现在介绍完了Exchange,可以再回过头来介绍Producer的规则。 当时说Producer会将消息发送给queue,现在我们知道Producer是将消息发送给了Exchange。Producer在发送消息的时候需要指定Exchange,也就是需要声明ExchangeName,同时根据指定的这个Exchange的类型,来设置一个routing-key。我们知道Exchange和queue是通过一个叫binding的key来完成的,在Exchange中会记录所有它连接的queue所对应的binding(暂且叫bs吧,也就是多个binding的集合),消息通过设置的ExchangeName发送到指定的这个Exchange,同时携带过去的routing-key会与bs中的binding进行匹配,匹配条件满足就会将消息发送过去(匹配到几个就发送几个)。
1 | Consumer连接queue的规则相对来说就简单很多了,指定queue的名字,设置几个连接参数就好了(比如说:exclusive、Auto-delete、Durable)。 |
另外对于Producer、Exchange、Queue,和Consumer都还有一些可设置的参数用来个性化配置,这个自己去搜索一下吧。
一张图来解释整个过程
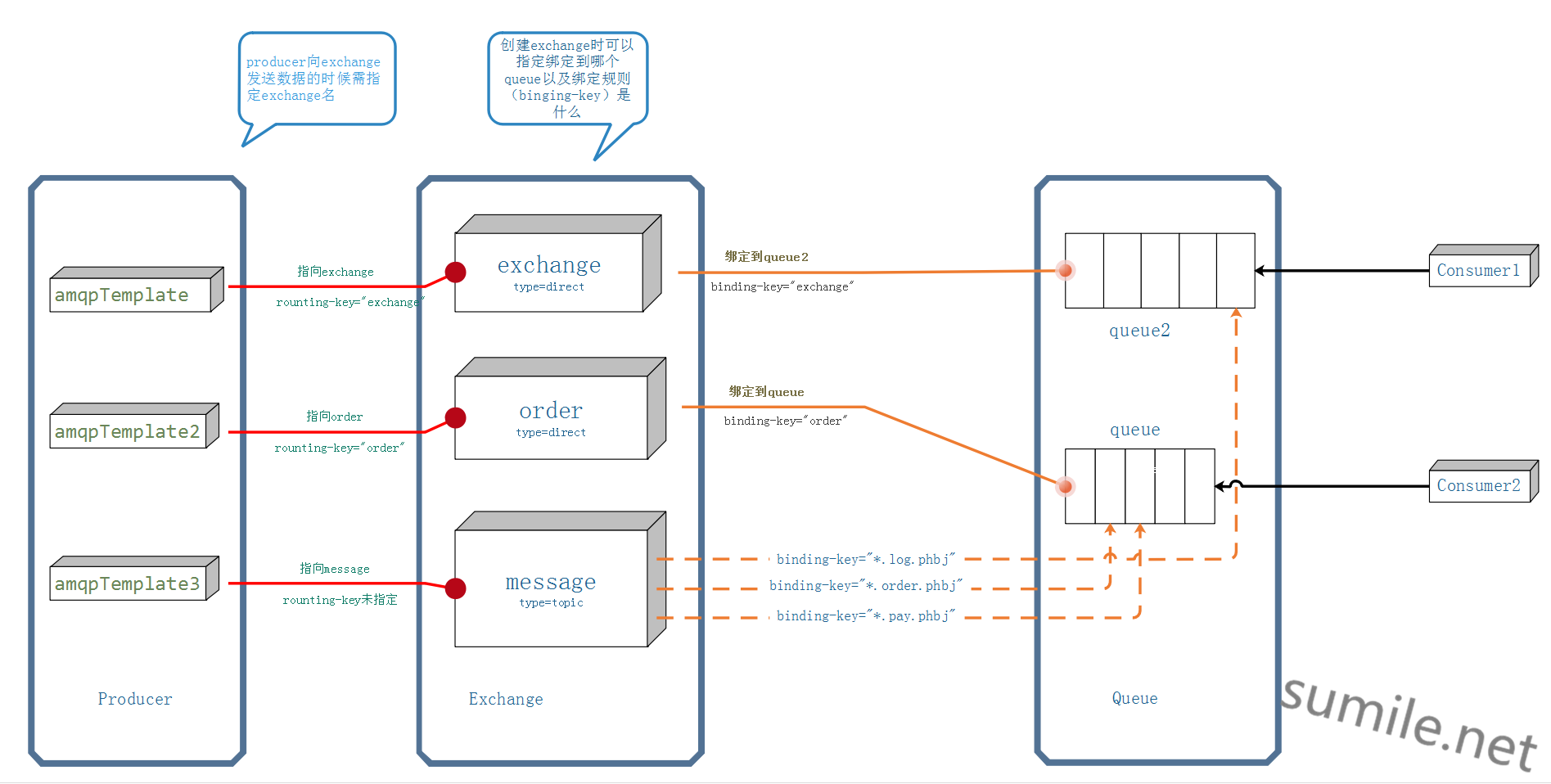 图中Producer发送消息给message,routing-key未指定是指没有固定一个routing-key,这个key是动态可变的。 而根据message这个Exchange的type可知,这个message是那么聪明的服务员,会根据规则将发送来的消息“聪明”的交给相应的Queue处理。 假如这个Producer发送的Message所指定的routing-key是order.log.phbj,那么根据Exchange与Queue间对应的橙色线,这条消息会被发送给queue2,并由Consumer接收处理。 如果这个Producer发送的Message所指定的routing-key是weixin.order.phbj,那么这个消息会被发送queue,并由对应注册的Consumer2接收(注意这里的Consumer可能不止一个,但是只会有一个Consumer来接收) 过程大概就是这样了,接下来配合Spring来使用。
图中Producer发送消息给message,routing-key未指定是指没有固定一个routing-key,这个key是动态可变的。 而根据message这个Exchange的type可知,这个message是那么聪明的服务员,会根据规则将发送来的消息“聪明”的交给相应的Queue处理。 假如这个Producer发送的Message所指定的routing-key是order.log.phbj,那么根据Exchange与Queue间对应的橙色线,这条消息会被发送给queue2,并由Consumer接收处理。 如果这个Producer发送的Message所指定的routing-key是weixin.order.phbj,那么这个消息会被发送queue,并由对应注册的Consumer2接收(注意这里的Consumer可能不止一个,但是只会有一个Consumer来接收) 过程大概就是这样了,接下来配合Spring来使用。
Spring中使用RabbitMQ
pom文件放在文章末尾,这里先来说RabbitMQ的配置文件
1 | <?xml version="1.0" encoding="UTF-8"?> |
在程序启动之前,首先来确认下RabbitMQ的状态  图中可以看出,现在没有连接链接到RabbitMQ,Exchange和Queue也都是空的。 然后启动程序
图中可以看出,现在没有连接链接到RabbitMQ,Exchange和Queue也都是空的。 然后启动程序 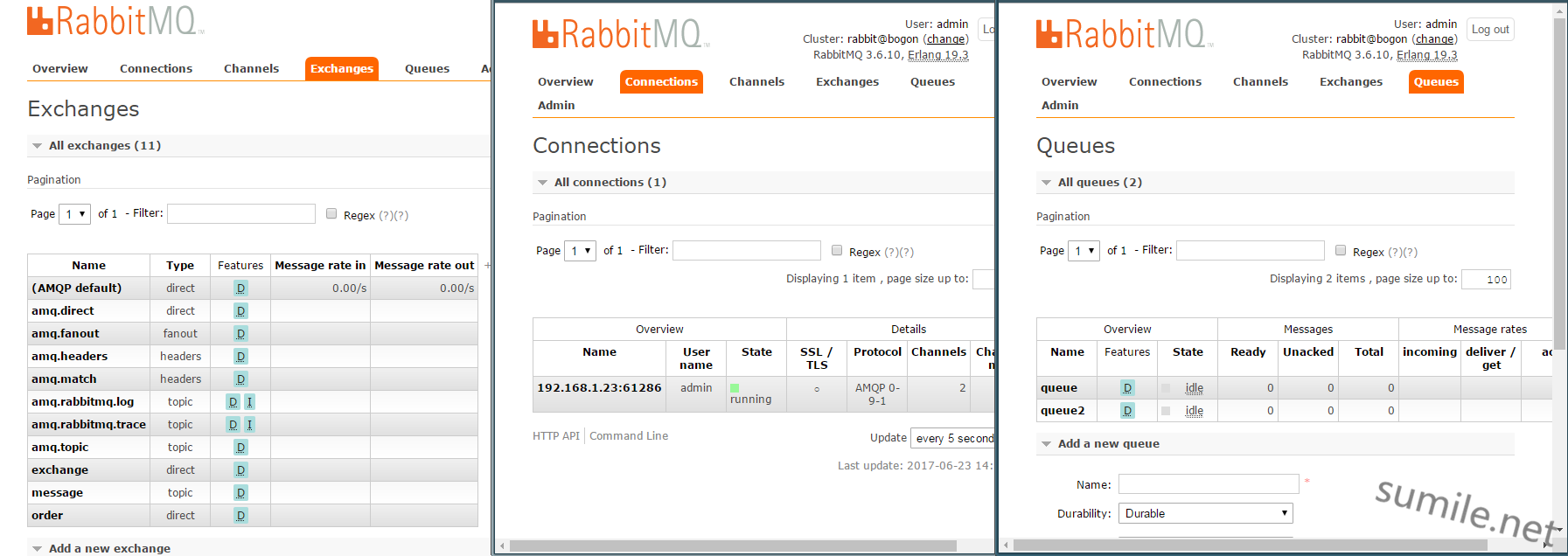 这是启动之后立刻就截的图,可以看到,有一个连接链接上了RabbitMQ,同时创建了三个Exchange以及两个queue。 然后打开每一个Exchange来看看它的对应规则是什么,着重看红色框中的
这是启动之后立刻就截的图,可以看到,有一个连接链接上了RabbitMQ,同时创建了三个Exchange以及两个queue。 然后打开每一个Exchange来看看它的对应规则是什么,着重看红色框中的  可以看到,红色框中的设置正是在xml中配置的那部分:
可以看到,红色框中的设置正是在xml中配置的那部分:
1 | <rabbit:direct-exchange name="order" durable="true" auto-delete="false"> |
其中配置文件中的“<rabbit:” 后面的topic和direct指该Exchange的类型。而绑定的queue则在bindings中,规则是通过binding配置的key或者pattern。这些在图中都有显示。 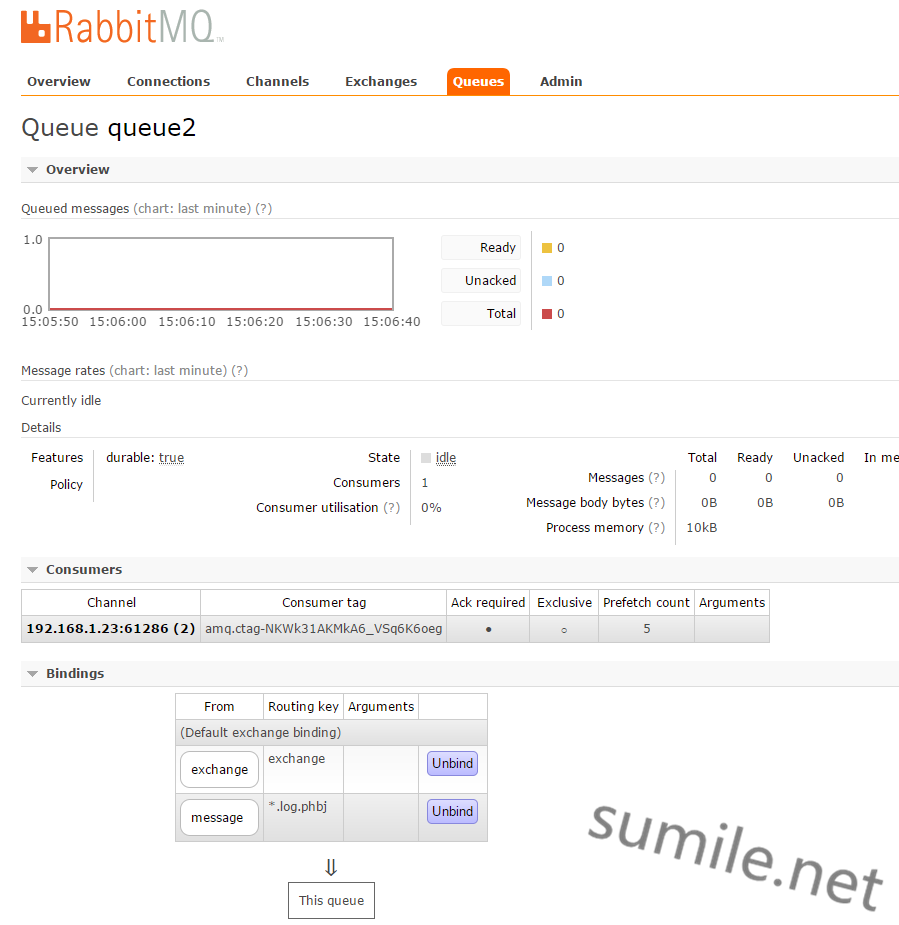 图中Bindings与上面的Exchange的配置有对应,而Consumers则对应了xml中的以下配置:
图中Bindings与上面的Exchange的配置有对应,而Consumers则对应了xml中的以下配置:
1 | <!--RabbitMQ 的 Consumer--> |
Ack required通过配置的acknowledge来配置,表示需要消息确认 Prefetch count通过配置中的prefetch标签配置,来限制Queue每次发送给每个消费者的消息数。
如果有多个消费者同时订阅同一个Queue中的消息,Queue中的消息会被平摊给多个消费者。这时如果每个消息的处理时间不同,就有可能会导致某些消费者一直在忙,而另外一些消费者很快就处理完手头工作并一直空闲的情况。我们可以通过设置prefetchCount来限制Queue每次发送给每个消费者的消息数,比如我们设置prefetchCount=1,则Queue每次给每个消费者发送一条消息;消费者处理完这条消息后Queue会再给该消费者发送一条消息。 参考:RabbitMQ基础概念详细介绍
发送者的相关配置不会在上面的图中体现,他是通过代码来调用运行的。
1 | <rabbit:template id="amqpTemplate" connection-factory="connectionFactory" |
我们在配置文件中配置了三个发送消息的模板,其中amqpTemplate和amqpTemplate2是两个普通的发送模板,它定义了exchange和routing-key。 而amqpTemplate3比较特殊,它定义了mandatory,这个用来标识这个模板发送的消息是否需要回执(当mandatory标志位设置为true时,如果exchange根据自身类型和消息routeKey无法找到一个符合条件的queue,那么会调用basic.return方法将消息返还给生产者;当mandatory设为false时,出现上述情形broker会直接将消息扔掉。) 这就是为什么需要使用bean标签而不使用<rabbit:template标签的原因。同时我们看到amqpTemplate和amqpTemplate2使用的connection-factory是connectionFactory,而amqpTemplate3使用的是rabbitConnectionFactory,这是因为如果需要回执的话,需要在Connection-Factory中指定一个参数publisherConfirms,从下面两个connection-factory的配置就可以看出:
1 | <rabbit:connection-factory id="connectionFactory" username="admin" password="123456" |
至此,配置文件与RabbitMQ的关系算是稍微的讲完了,解下来,我们实测一下。
实测运行
先放Controler文件以及其他一些文件 Controler
1 | package net.sumile.controler; |
以及MessageProducer
1 | package net.sumile.producer; |
以及两个接收者中的一个,另外一个类似,只是输出的文字由Queue替换为了Queue2用来区分接收的是哪个queue中的message
1 | package net.sumile.consumer; |
最重要的就是这几个文件,来捋一遍过程: 首先通过浏览器访问一个我们的服务器地址,进入controler,根据传过来的type去调用不同的模板发送不同的消息,然后由对应的Consumer接收并打印出来。
-
请求地址:http://localhost:8080/home?type=1&routing_key=myO.pay.phbj&message=k 打印:
1发送:k
接收到Queue2:k因为template对应的Exchange是exchange,而exchange对应的queue是queue2,所以打印出来的接受者是queue2
-
请求地址:http://localhost:8080/home?type=2&routing_key=myO.pay.phbj&message=65 打印:
2发送:65
接收到Queue:65原理同上
-
请求地址:http://localhost:8080/home?type=3&routing_key=myO.pay.phbj&message=65 打印:
2发送:65
接收到Queue:65原理同上
-
请求地址:http://localhost:8080/home?type=3&routing_key=myO.pay.phbj&message=65 打印:
3发送:[65] routing-key = [myO.pay.phbj]
接收到Queue:65这里routing_key匹配到了*.pay.phbj,所以发送到queue中并由queue的Consumer接收
-
请求地址:http://localhost:8080/home?type=3&routing_key=myO.log.phbj&message=65 打印:
3发送:[65] routing-key = [myO.log.phbj]
接收到Queue2:65这里routing_key匹配到了*.log.phbj,所以发送到queue2中并由queue2的Consumer接收
confirmCallback和returnCallback
接下来我们来看一组请求: 请求地址:http://localhost:8080/home?type=3&touting_key=myO.l2og.phbj&message=65 看这组请求,我们知道是调用amqpTemplate3来发送的,但是并没有binding-key与之对应,所以这个Message发送到Exchange之后Exchange不知道该交给哪个Queue。但是由于我们设置了
1 | <property name="returnCallback" ref="returnCallBackListener"/> |
所以如果Exchange没有找到匹配的queue的时候,就会进入到这个类的方法中,由我们来处理这条迷路的Message,不至于将这条消息丢失了。 那这个配置是做什么的呢?
1 | <property name="confirmCallback" ref="confirmCallBackListener"/> |
简单来说,如果发送出去的消息找不到Exchange,到confirmCallback中,如果找到了Exchange找不到Queue,到returnCallback中。其余的可以参考这个RabbitMQ(四)消息确认(发送确认,接收确认),如果要测试的话我们可以不停的发送消息,然后手动的将要路由到的queue删掉,就会出现这种情况了。
Consumer的回复
我们在Consumer的配置中设置了acknowledge参数,表示需要手动回复“已经接收到该消息”然后queue才会删除该Message。 下面来实测下如果不回复会怎么样 我们将MessageConsumer 中的回复代码注释掉,并请求地址:http://localhost:8080/home?type=2&routing_key=myO.pay.phbj&message=65。看看RabbitMQ中queue里面Message是怎么变化的
1 | public class MessageConsumer implements ChannelAwareMessageListener { |
我们请求三遍上面的那个地址,然后去看控制台,会看到回复:
2发送:65
接收到Queue:65
2发送:65
接收到Queue:65
2发送:65
接收到Queue:65
接收到了。然后再去看RabbitMQ的网页控制端:http://192.168.1.198:15672 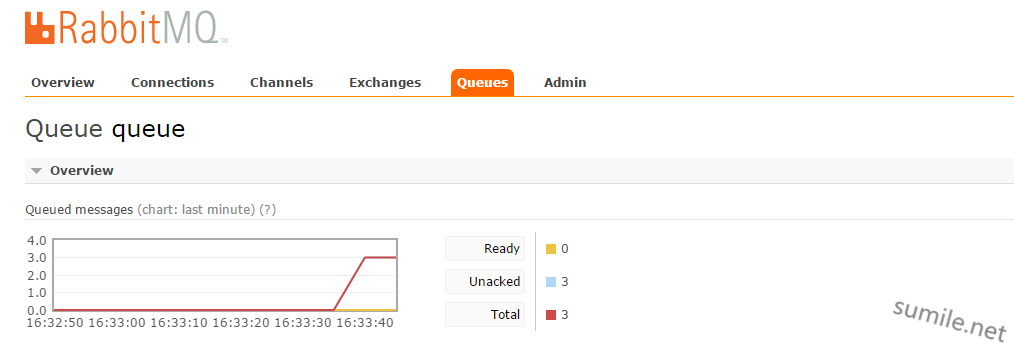 queue中累计了三条消息,而这三条消息已经是处理过的,如果有消息不停的进入,结果就是堆满内存 这是最需要注意的一点 都是自己在实际了解学习过程中遇到的一些问题以及感悟,看了很多博客,感谢各位大牛。 有错误请指出,望不吝赐教。
queue中累计了三条消息,而这三条消息已经是处理过的,如果有消息不停的进入,结果就是堆满内存 这是最需要注意的一点 都是自己在实际了解学习过程中遇到的一些问题以及感悟,看了很多博客,感谢各位大牛。 有错误请指出,望不吝赐教。
RabbitMQ-Demo
